
Can technology protect AI work, or only prove it?
Last updated: Feb 26, 2026

You finish a clip you’re genuinely proud of, the kind that took time in the edit even if the raw material started as prompts. Then you pause. Not because you’re second-guessing the work, but because you’re wondering what happens once it’s out in the open.
Maybe you’ve already seen the pattern. A near-copy shows up with the same rhythm and the same key beats, just enough changed to feel plausible. Or your original is re-cut and re-captioned so the meaning shifts, and people start reacting to something you didn’t make. None of that has to be catastrophic to be annoying and time-consuming. It can be enough to make you think twice about what you share and how you prove what’s yours.
This guide is for creatives and production teams delivering AI-assisted work, plus the brands and agencies commissioning it. It looks at what technology can realistically do to support protection, proof, and traceability, and what still depends on your workflow and documentation.
A disclaimer and what protect really means
This is workflow guidance, not legal advice. Copyright and AI rules vary by country and context, and platform policies change, so professional advice can be sensible for real disputes or commercial campaigns.
It also helps to define what protect means, because different tools solve different problems.
Deterrence, making casual misuse less likely
Proof, making it easier to show what happened and when
Discovery, helping you find reposts and near-copies
Control, limiting who can access assets before release
If you need the wider workflow around ownership layers, permissions, and what to do when something goes wrong, it’s mapped out in how to prove you made it. This post stays narrower on purpose, focusing on the technical signals and checks that can support a proof trail, plus the practical habits that help you show what happened if a clip is reused, re-edited, or misattributed.
If you work across regions, it helps to see how the topic is being framed in official language, because that framing can shape how disputes are discussed long before anything becomes formal. The UK government consultation on copyright and AI is a useful reference point for the UK side of that conversation.
For a US reference that’s widely cited in industry discussions, the U.S. Copyright Office AI guidance hub is useful for checking what is being treated as guidance, what is still unsettled, and where human authorship is emphasised.
The core technical methods and when each one applies
A lot of summaries list five methods and treat them as interchangeable. They’re not. In practice, they fall into two buckets.
One bucket supports an origin trail and reuse discovery after publication. The other helps you reduce leakage before publication.
Here are the methods that matter most, with the job each one can realistically do.
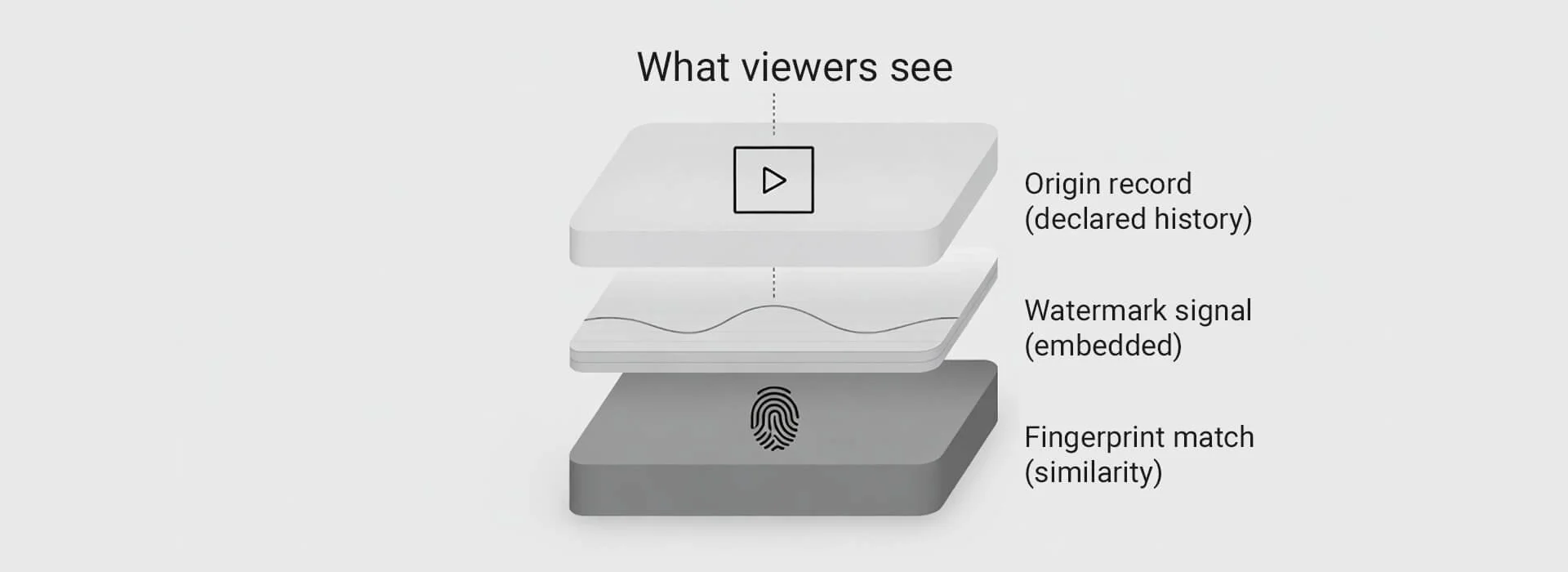
A single clip can carry multiple signals, but your evidence pack and versioning stay in your control.
1) Origin records, often surfaced as Content Credentials
When people say Content Credentials, they’re usually talking about an origin record standard called C2PA, and the C2PA explainer is the clearest starting point for what it is and what it claims to record. It also helps you keep expectations realistic, because these records only help if they survive export and upload.
2) Watermarking
Watermarking embeds a signal into the content itself. Some watermarks are visible, some are designed to be imperceptible and machine detectable. Watermarks can be weakened by compression, cropping, and heavy re-encoding, so they’re best treated as one signal among several. Some systems aim to embed detection signals into generated media itself rather than relying only on metadata, and Google DeepMind SynthID is a good example of that watermarking direction of travel.
3) Fingerprinting and perceptual hashing
Fingerprinting tries to match content based on similarity, even after common edits like resizing, trimming, or re-encoding. This can help you find reposts and near-copies, but it does not automatically tell you whether use is authorised. If you want a clear explanation of the approach and its limits, Ofcom’s overview of perceptual hashing is a solid UK-friendly reference.
Even before AI, platforms have used matching systems at scale. YouTube’s Content ID scans uploads against reference audio and video supplied by rights holders, and matches can result in a claim with actions such as monetise, track, or block. The key detail is that matching is not the same as licensing, and How Content ID works explains why claims can still happen even where a licence exists.
If you want a sense of the scale at which matching and claims operate on major platforms, the YouTube Copyright Transparency Report gives useful context, even though it will not predict what happens in any single dispute.
4) Do not train signals and rights reservations
Some creators register work or publish signals that request exclusion from training datasets. These mechanisms may be respected by some developers, but they’re not a universal lock, and they don’t rewind past scraping. For a creator-facing explanation of what these signals are trying to communicate, the Spawning guide to rights reservations is practical.
If you want a neutral international source that stays careful about uncertainty and jurisdiction differences, WIPO guidance on generative AI and IP is a useful anchor for the wider context around ownership and protection debates.
5) Access control, encryption, and API gating
These are most relevant when the work is not public yet, such as drafts, source assets, prompt logs, project files, or client review exports. They reduce leakage, limit scraping, and give you clearer audit trails of who accessed what. They won’t stop copying of what someone can already see, but they can reduce untracked sharing.
When you want a cautious technical reference that doesn’t oversell what detection can guarantee, the NIST overview on reducing risks from synthetic content is a grounded place to align expectations around transparency tooling and trade-offs.
Build an origin trail that survives handoffs
The biggest mistake is relying on a single marker. Metadata can be stripped, watermarks can degrade, and fingerprint matches can be messy in edge cases. The reliable move is to keep a compact origin trail that makes your story easy to evidence.
An origin trail is less about capturing everything and more about capturing what you’ll be asked about later.
What file was approved and published
What tools materially shaped the output
What changed between versions
What rights or permissions sit behind the inputs that matter
To make it repeatable, use a folder structure you can reuse. This keeps evidence, permissions, and versions easy to find when you’re under pressure.
| Folder | What goes in it | Why it matters | Quick naming tip |
|---|---|---|---|
| 00 Admin and brief | Brief, scope notes, creative intent, client requirements | Shows context and intent | YYYY-MM-DD_brief_v01.pdf |
| 01 Licences and permissions | Licences, releases, approvals, usage scope notes | Supports rights and consent without hunting | release_name_role_signed.pdf |
| 02 Source assets | Any non-generated inputs, stock, music, logos, references | Shows what you brought in and under what terms | asset_vendor_id.ext |
| 03 Project files and timelines | NLE project files, key comps, grade nodes, LUTs | Shows human shaping and edit decisions | project_v03.prproj |
| 04 Exports master | Final masters, highest quality, unchanged after sign-off | Reference file if anything is disputed | master_v01_YYYY-MM-DD.mov |
| 05 Exports upload | Platform versions, captions, thumbnails, aspect variants | Shows what you actually published | yt_16x9_v02.mp4 |
| 06 Origin record checks | Verification screenshots, reports, hashes, notes | Captures what signals existed at release | verify_master_YYYY-MM-DD.png |
| 07 Change log | Major changes, approvals, dates, who signed off | Makes the story easy to explain quickly | changelog.md |
If you build this folder alongside the project from day one, it stays light. Trying to reconstruct it later tends to be slow and stressful.
If faces, voices, or identifiable people are involved, it’s worth grounding the conversation in UK expectations, and ICO guidance on AI and data protection is a practical baseline for thinking about risk, fairness, and accountability.
For a UK organisational view of how origin records fit into real systems and trade-offs, NCSC guidance on selecting suitable systems is helpful, even if the URL uses more technical language than the post does.
Two habits keep this safer.
Write the log in factual language, what was done, by whom, with which tool
Avoid statements that imply certainty about detection or legal outcomes
Test what survives export and upload
A file can look identical to a viewer and still lose its origin record after export or platform processing. That’s why a verification gate matters.
Run this short protocol on any project where proof or disclosure may matter. Run it once per platform you publish to, and repeat if your export settings change.
Check the master export for an origin record
Check the upload export for an origin record
Upload to your main platform, then download what the platform serves back
Check the downloaded version
Save the results and note export settings and platform behaviour
To make the verification gate concrete, Verify Content Credentials is a practical tool for checking whether an origin record is present in a file before and after export and upload.
Then use one decision rule that keeps you out of trouble.
If an origin record survives, describe it as a record of declared history, not as proof of truth
If an origin record does not survive, rely on your evidence pack and clear versioning
If watermarking or fingerprinting suggests a match, treat it as a lead that may need corroboration
Key takeaways
Technology can support protection, but it’s usually better at proof and discovery than prevention
Origin records can strengthen your origin trail when they survive export and publishing
Watermarks and fingerprints can support discovery, but neither automatically proves authorisation
Access control matters most before release, when you can still limit leakage
A compact evidence pack plus a verification gate tends to hold up better than any single tool